Reference v/s Duplicate in Power BI
Finally, we are back with new blogs. The idea of all the blogs is to share the problem of the week which I faced and provide a solution to it. So, as Business Intelligence Analyst one of my major responsibilities is to design an optimized data model and avoid many to many relationships. The primitive approach to such a problem is to create bridge tables out of a big flat table and create one to many relationships in that process.
Creating bridge tables can be achieved in the Power Query Editor. There are mainly two ways to achieve that one is to take reference tables and the other is to create a duplicate table out of the big flat table. So what is the difference between duplicate and reference? Let's dig deeper into it. If you see both of them create a copy of the main table but in duplicate, it will copy the changes applied to the main table whilst in the reference the bridge table will be isolated from all the changes applied to the main table.
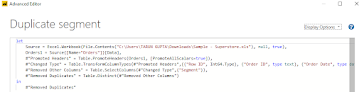
The reference query always points to the main table and does not copy any of the applied steps to the main query. Let's see how does it work in Power BI. I am currently using the Sample Superstore Data. You just need to right-click on the main table and you will see both duplicate and reference.

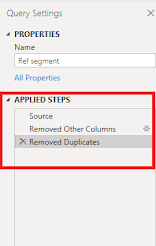
At first, we are creating a reference table out of the orders table and to avoid many to many relationships we will remove duplicates from the segment column. I have removed all other columns because I will set up a segment table and create relationships with other tables.

If you do that you will get a column with only three rows. Now let's see the m-script and query dependencies behind this reference. To see that you need to go to the view tab and there you can find both the options.






Comments
Post a Comment